Exchange 2013: Cumulative Update 6 Installation
On August 26, 2014 Microsoft released the cumulative update 6 so I decided to deploy and share the screens of my deployment.
Important warning: Please give 30 days to let the new update settle down and test in your lab before deployment in the production because I won’t be able to test everything in my lab which you have in your environment.
We also shared the release notes here.
Let us begin the deployment.
Follow the basic prerequisite from here or here.
Download the Exchange 2013 CU6 from here.
Make sure you have following group membership:
Domain Admins
Schema Admins
Enterprise Admins
Extract CU6 then run the setup with Run as administrator.
Click yes here
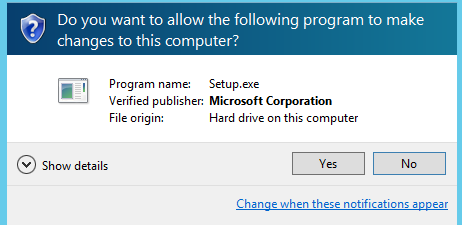
Select “Don’t check for updates right now” and click next
Let the setup copy files then click next on the introduction page.
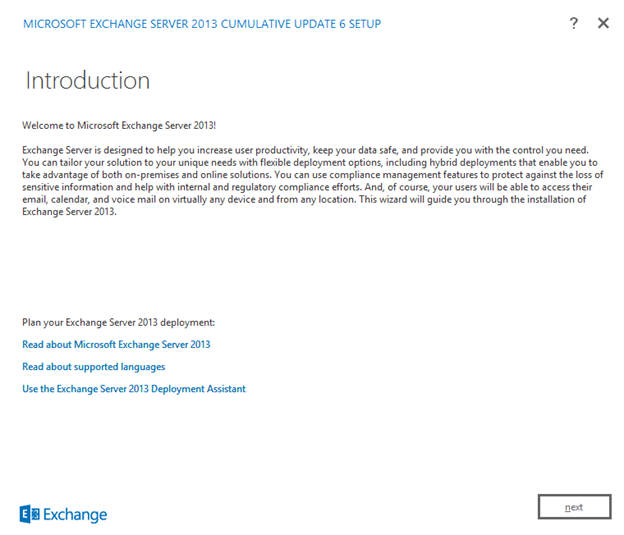
Select I accept then click next
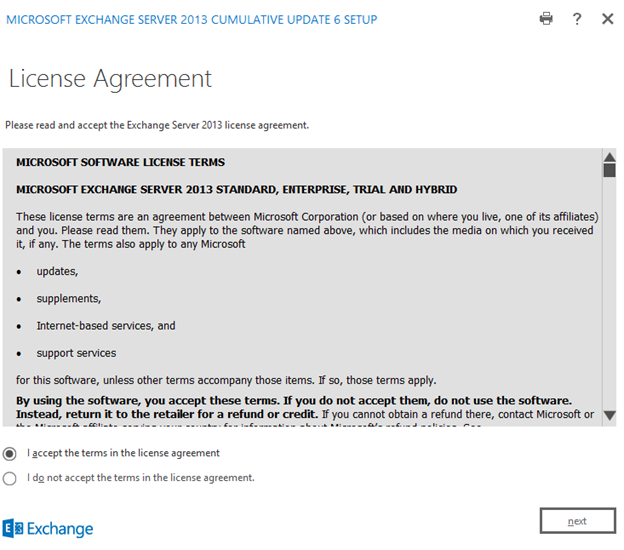
Select “Don’t use recommended settings” and click next
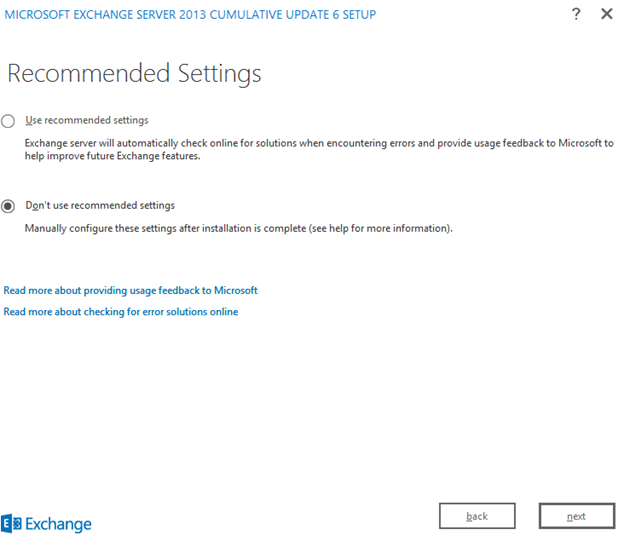
Select server role and click next. I selected mailbox and Client access role.
Provide the location for the exchange installation files then click next
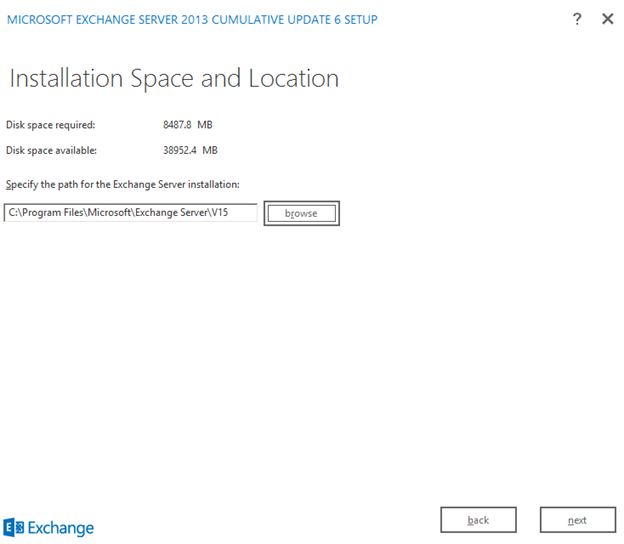
Keep the default setting No on Malware Protection Settings page and click next.
Readiness checks should come clean, click install to install the Exchange 2013 CU6
Setup will have 14-15 steps. Once setup finish, click on Finish and restart the server.
After the restart of the server, access the Exchange admin center and check the services.
Another simple deployment finished.
Prabhat Nigam
Microsoft Solutions Architect | Exchange Server
Team@MSExchangeGuru
")


August 29th, 2014 at 3:20 pm
Do not install this CU6 if you have a 2007COEX with EX13. Were having major issues with databases flapping. This is due to EX07 mailboxes talking to EX13 mailboxes. MS are aware of this and working on a fix now.
FYI!
August 29th, 2014 at 3:36 pm
Thank you Ryan for the update. I will talk to the Product Group about it.
August 29th, 2014 at 11:30 pm
Here is the more update from MS: This happens when a 2007 user attempts to access a delegated mailbox that is on a 2013 server. This issue is being tracked by KB2997209, that is still being published.
August 30th, 2014 at 4:39 pm
Hotfix and KB released – http://support.microsoft.com/kb/2997209/en-us
September 1st, 2014 at 12:09 pm
[…] facing an issue with CU6 in exchange 2007 mix mode here. Any confirmation will be appreciated. https://msexchangeguru.com/2014/08/28/e2013cu6installation/ Following issue reported. =================================================== Do not install […]
September 2nd, 2014 at 5:07 pm
Hi Guys,
Just a warning – If you are running 2013/2007 coexistence you will have the following issues:
1. Delegated Mailboxes causing store service crash (and failover in DAG group where applicable) – KB2997209 does fix the issue but you will have to log a support ticket.
2. Exchange 2013 proxy for activesync WILL BREAK for legacy 2007 mailboxes – I am currently working with MS to resolve but so far there is no fix. They have multiple other customers with the same issue.
Oh and CU6 promised to fix the Hybrid Configuration Wizard (which is why we installed it in the first place) – but it just created another error on the wizard now…
-NotAHappyMicrosoftCustomer
September 2nd, 2014 at 11:38 pm
@Marcus
You should have posted the issue here (we are tracking the issues here)- https://msexchangeguru.com/2014/08/30/e2013cu6-dontdeployif/
Microsoft released the script for hybrid customer which needs to fix the script
http://support.microsoft.com/kb/2997355
Update the script if exchange is not installed in the default c drive path.
$baseDirectory = “$Env:ExchangeInstallPath” +”ClientAccess\ecp\DDI”
I will report the proxy issue now.
September 2nd, 2014 at 11:55 pm
[…] issue was posted here in the comments of this blog post: https://msexchangeguru.com/2014/08/28/e2013cu6installation/. This issue has NOT been confirmed by Microsoft […]
September 8th, 2014 at 4:32 pm
@Marcus
Here is the Update from MS
We will be publishing KB2997847 later today for the 2007/2013 EAS proxy issue. All customers can now request a combined fix for both 2007/2013 co-existence issues. Both of these fixes will be available in our next cumulative update.
September 12th, 2014 at 3:57 am
Did you encounter any problems with IMAP after deploying CU6?
If you use any client that uses IMAP I get “Command error. 12” on any operation (move e-mail, delete etc.).
September 12th, 2014 at 3:44 pm
It seems that mentioned fix (http://support.microsoft.com/kb/2997355) doesn’t do the trick. After installing CU6 file which is altered in the script cannot be found (RemoteDomains.xaml).
One more thing, after installing CU6 we are experincing issue with IMAP and Thunderbird. It seems that commands like move are interpreted by the server as bad commands (error 12).
September 14th, 2014 at 2:57 am
@Peter
Please share more description
September 14th, 2014 at 8:42 am
1st thing, I’m missing O365 part from ECP which now leads to some offical Office site (this issue is described here – http://www.expta.com/2014/08/dont-deploy-exchange-2013-cu6-if-youre.html). There is an information that fix was released by Microsoft (http://support.microsoft.com/kb/2997355) but it doesn’t work. Fix contains PowerShell script which changes file (RemoteDomains.xaml) in ECP/DDI direcotry. The funny thing is that there is no such file on Exchange Serves in mine environment (updated version of the script that look for Exchange installation folder in registry doesn’t change the fact that file doesn’t exist).
2nd thing, problem with IMAP. Below you can find error message from Thunderbird client:
(…)somemailserver:S-INBOX:ProcessCurrentURL:imap://someuser@somemailserver:993/onlinemove%3EUID%3E/INBOX%3E947873%3E/Trash: = currentUrl
(…)somemailserver:S-INBOX:SendData: 21 uid move 947873 “Trash”
(…)ReadNextLine [stream=1b0fb310 nb=26 needmore=0]
(…)somemailserver:S-INBOX:CreateNewLineFromSocket: 21 BAD Command Error. 12
Exchange Server after update presents following capabilities for IMAP:
* OK The Microsoft Exchange IMAP4 service is ready.
* CAPABILITY
* CAPABILITY IMAP4 IMAP4rev1 AUTH=PLAIN UIDPLUS MOVE CHILDREN IDLE NAMESPACE LITERAL+
* OK CAPABILITY completed.
If I’ll use mailbox that was moved to cloud (O365) Thunderbird works without any problem. This issue appeared after applying CU6 to our servers.
September 16th, 2014 at 11:25 am
After installing CU6, users started experiencing problems with Inbox Rules.
Rules don’t work at times, also outlook crashes when you open rules and alerts or rename a rule.
our Exchange 2010 users are perfectly fine, exchange 2013 users all have this issue.
September 16th, 2014 at 11:39 am
Sorry to hear this Muhammad. Could you open a ticket with Microsoft, they should not charge you for this.
September 16th, 2014 at 11:57 am
After installing CU6 servers are randomly rebooting from Bugchecks 0x0ef. Related to:
ROCESS_OBJECT: ffffe0007194a080
IMAGE_NAME: wininit.exe
DEBUG_FLR_IMAGE_TIMESTAMP: 0
MODULE_NAME: wininit
FAULTING_MODULE: 0000000000000000
PROCESS_NAME: MSExchangeHMWo
BUGCHECK_STR: 0xEF_MSExchangeHMWo
DEFAULT_BUCKET_ID: WIN8_DRIVER_FAULT
October 30th, 2014 at 3:45 am
@Darren C,
That same bugcheck has been around since CU2 I wish MS would get off their arse and fix it..
I was hoping to hell that CU6 would fix it.
The issue is the Exchange Health Monitoring service, it causes the server to try and “self heel”.
When it doesn’t, a bugcheck is produced and then a reboot occurs.
You have probably seen the links to this by now so I won’t bother putting them here unless someone asks for them.
Cheers,
H.
October 31st, 2014 at 1:56 pm
I’m performing a CU6 update on an Exchange 2013 this weekend.
This is part of a migration from Exchange 2007 which was ended past monday 27th October.
We’ve been having issues with Exchange 2013 after Exchange 2007 decommission, and Microsoft Support stated that it would not proceed before the CU6 is applied.
The main issues are problems with active sync, where mobile devices loose connectivity with the mailboxes, and also Exchange 2013 sometimes gets extremely slow and takes me sometimes 1 hour to reboot and have all services running again.
Well, after the reports I see in here about CU6 installation, I’m a bit concerned.
You guys think it’s the correct step to do?
@Hamish,
can you share the info you have about the Health Monitoring issues?
thank you
November 13th, 2014 at 7:18 pm
Hi Paulo,
I found that I was getting the same bugchecks as Darren C, and just this week have found that since stopping the health monitoring service I continued to get more.
From the investigations I’ve done, it appears that the Health Monitoring service was “masking” the real bugcheck issues at the OS layer since the monitoring service is application layer based, I couldn’t see the root cause.
It in fact turned out to be the VMWare Vshield driver. I’ll explain it in a condensed manner:
Environment = 6 Exchange servers, two DAGS with three nodes. 2 nodes in one DC and one in another for each DAG. All Exch servers running CAS and Mailbox roles as you would expect in this configuration.
Extract from Bugchecks taken from two of the servers, other two have same entries or Darren C’s bugcheck:
IRQL_NOT_LESS_OR_EQUAL (a)
An attempt was made to access a pageable (or completely invalid) address at an
interrupt request level (IRQL) that is too high. This is usually
caused by drivers using improper addresses.
SYMBOL_STACK_INDEX: 4
SYMBOL_NAME: vnetflt+1b24
FOLLOWUP_NAME: MachineOwner
MODULE_NAME: vnetflt
IMAGE_NAME: vnetflt.sys
Appears to be related to the vShield driver version, my company was on 5.5 update 1, need to go to 5.5 update 2
http://kb.vmware.com/selfservice/microsites/search.do?language=en_US&cmd=displayKC&externalId=2077302
DRIVER_CORRUPTED_EXPOOL (c5)
An attempt was made to access a pageable (or completely invalid) address at an
interrupt request level (IRQL) that is too high. This is
caused by drivers that have corrupted the system pool. Run the driver
verifier against any new (or suspect) drivers, and if that doesn’t turn up
the culprit, then use gflags to enable special pool.
Arguments:
Arg1: 00000001b1a58040, memory referenced
Arg2: 0000000000000002, IRQL
Arg3: 0000000000000000, value 0 = read operation, 1 = write operation
Arg4: fffff802ce50a0d0, address which referenced memory
LAST_CONTROL_TRANSFER: from fffff802ce3d5ae9 to fffff802ce3c9fa0
STACK_TEXT:
ffffd000`c8e25118 fffff802`ce3d5ae9 : 00000000`0000000a 00000001`b1a58040 00000000`00000002 00000000`00000000 : nt!KeBugCheckEx
ffffd000`c8e25120 fffff802`ce3d433a : 00000000`00000000 00000000`00000000 00000000`00000000 ffffd000`c8e25260 : nt!KiBugCheckDispatch+0x69
ffffd000`c8e25260 fffff802`ce50a0d0 : ffffe001`b13f8890 00000000`00000000 00000000`00000001 fffff802`ce361199 : nt!KiPageFault+0x23a
ffffd000`c8e253f0 fffff802`ce50ba24 : ffffe001`b138c660 ffffe001`b13f8890 00000000`00000000 00000000`00000002 : nt!ExDeferredFreePool+0xc0
ffffd000`c8e25470 fffff801`374192f2 : 00000000`00000000 fffff801`3757be80 ffffe001`b1a4faf8 fffff802`6c694656 : nt!ExFreePoolWithTag+0x744
ffffd000`c8e25540 00000000`00000000 : fffff801`3757be80 ffffe001`b1a4faf8 fffff802`6c694656 ffffe001`b1a4fae0 : vsepflt+0x192f2
Points to the updating the driver again:
http://kb.vmware.com/selfservice/microsites/search.do?language=en_US&cmd=displayKC&externalId=2081616
Now you need to be careful here on what hosts you are running. We have found that HP hosts we have failed when this update was applied to them. BIOS needed to be updated to the latest version released a few days ago to complement 5.5 update 2.
Re CU6 itself, I’m in a situation where there is another vendor that controls AD so I can’t prep AD schema or configuration partition myself. I gave them the change control information to do it, and what checks to run, and they have just done this for me last night (13/11/14).
I’m going to roll CU6 in the next week or so anyways. Unfortunately I also had a SAN failure for the VM farm in one of the DC’s where one of the Exchange DAG’s is hosted yesterday so had to do a DR failover from the primary to secondary DC yesterday, so this is holding things up.
From what I have just had to do in an real DR scenario, I can tell you now that the steps everyone touts as being how to recover the DAG into the DR site we partially correct, and I now know what commands need to be run in order to get a single node back up with an AFSW.. But that’s another story, maybe I should put that out for people as by the looks of things most of the stuff I’ve seen is by guys in their labs! No offense intended dudes, but real life is a bit different. 😉
Cheers,
Hamish