Exchange 2010 Cross Site DAG Disaster Recovery: Data Center/AD Site failure Part 1
This article is a complete guide on performing Exchange 2010 Disaster recovery when you have a data center or Active directory failure in the primary site. This is going to work when DAG is expanded to at least 2 data centers & one of them is primary and other is DR site Datacenter.
This is the part of 1 of 2 of DAG Site DR guide.
Part 2 – Switchback to the Production Site – https://msexchangeguru.com/2012/10/30/exchange-2010-dag-dr2
Part 1 – Activating DR site
Assumption and pre-requisites
- Both Production and DR sites are replicating perfectly
- DAG with DAC is enabled
- All Prod and DR servers has same configuration.
- FIM will not work until Production AD site come up in a Site DR scenario.
- User is part of organization management AD exchange group.
- PF Database is available in the DR site
The following are the general procedures for failing over the Production Datacentre site to the DR site. By combining the native site resilience capabilities in Microsoft Exchange Server 2010 with proper planning, a second datacentre can be rapidly activated to serve the failed datacentre’s clients. A datacentre or site failure is managed differently from the types of failures that can cause a server or database failover. In a high availability configuration, automatic recovery is initiated by the system and the failure typically leaves the messaging system in a fully functional state. By contrast, a datacentre failure is considered to be a disaster recovery event, and recovery must be manually performed and completed for the client service to be restored, and for the outage to end. The process you perform is referred to as a datacentre switchover. As with many disaster recovery scenarios, prior planning and preparation for a datacentre switchover can simplify the recovery process and reduce the duration of the outage. We consider the SLA time to 4 hours which is good enough for the switch to the DR site. I am only concerned about the switching of the Public DNS host record for the CAS URLs and SMTP MX record/s.
Activating DR Site outage:
Users will have no access from any client until we bring the DAG up and Running. This will be a complete outage.
Estimated Time:
This will take 2 to 3 hours to bring DR up and running.
DR Activation Steps:
-
Backup: Take System State Backup of AD server in DR site.
- Go to all programs à Accessoriesà System Tools – Windows server backup.
-
Select backup once àDifferent OptionsàCustomàClick NextàAdd Items àCheck the checkbox in front of system state àLocal drives àSelect C drive in backup destination àClick on Backup
- Go to all programs à Accessoriesà System Tools – Windows server backup.
-
Change of the Public DNS host record for CAS and MX record from Production datacentre to DR data centre.
- Seize all FSMO roles from Production DC to the DR DC.
Run the below command to check the current FSMO role holder – Netdom query FSMO
- Log on to DR Domain Controller.
- Assign your account as member of Enterprise Admins, schema admins and Domain Admins.
- Logoff from DR Domain Controller to apply the group membership change.
- Login to DR Domain Controller.
- Open cmd prompt with run as administrator.
- Type ntdsutil then press enter.

Type roles, and then press ENTER.

Type connections, and then press ENTER.

Type “connect to server DR DCname”, and then press ENTER.
At the server connections prompt, type q, and then press ENTER.

Type “seize rid master” then press ENTER.
Type “Seize domain naming master” then press ENTER
Type “Seize infrastructure master” then press ENTER
Type “Seize PDC” then press ENTER
Type “Seize schema master” then press ENTER
You will receive a warning window every time we seize fsmo role, asking if you want to perform the seize. Click Yes here.
At the fsmo maintenance prompt, type q and then press ENTER.
Type q, and then press ENTER to quit the Ntdsutil utility.
Ensure DNS is working fine and resolving all required servers.
Move the File share witness and Database to DR Site:
In DAC mode we will run the following cmdlets:
Run the following cmdlet for all Production servers:
Stop-DatabaseAvailabilityGroup -Identity DAGname -mailboxserver ProdDAGservername1 –ConfigurationOnly
Login to the DR servers one by one and stop cluster service using below steps
Open cmd prompt with run as administrator
Type “Net stop clussvc” then press enter.
On one of the DR DAG exchange server, Open the Exchange Management Shell with run as administrator and run the following cmdlet:
Restore-DatabaseAvailabilityGroup -Identity DAGname -ActiveDirectorySite “DR AD site DN” -AlternateWitnessDirectory “alt fsw path” -AlternateWitnessServer “FQDN of Alternate FSW server”
Database should be mounted on DR servers after the completion of the above cmdlet.
If we see the similar error mentioned below:
Server “Production servers” in database availability group “DAGname” is marked to be stopped, but couldn’t be removed from the cluster. Error: A server-side database availability group operation failed. Error: The operation Failed. CreateCluster errors may result from incorrectly configured static addresses. Error: An error occurred while attempting a cluster operation. Error: Cluster API ‘”EvictClusterNodeEx(‘fqdn of one of the prod server’) failed with 0x46. Error: The remote server has been paused or is in the process of being started”‘ failed. [Server: fqdn of the DR server]
+ CategoreyInfo : InvalidArguement: <:> [Restore-DatabaseAvailabilityGroup], FailedToEvictNodeException
+ FullyQualifiedErrorId : B31DF5AF.Microsoft.Exchange.Management.SystemConfigurationTasks.RestoreDatabaseAvailabilityGroup
We should also check the log file for the error: Sample log file name is mentioned below.
dagtask_date_time_restore-databaseavailabilitygroup.log
-
Login to the DR servers one by one.
- Open Server Manager, start/restart cluster service.
- Open Server Manager, start/restart cluster service.
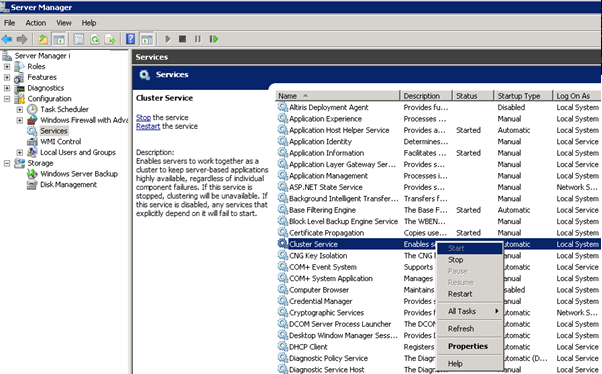
On one of the DR DAG exchange server, Open the Exchange Management Shell with run as administrator and re-run the following cmdlet:
Restore-DatabaseAvailabilityGroup -Identity DAGname -ActiveDirectorySite “DR AD site DN” -AlternateWitnessDirectory “alt fsw path” -AlternateWitnessServer “FQDN of Alternate FSW server”
Result should be coming clean similar to the below: The warning can be ignored because this is a FSW on a Domain Controller.
Have a dedicated FSW server for production environment.
Restoring Mailbox servers for the Active Directory site “DN of the AD site” in Database Availability Group “DAGName”
After this step database should be mounted.
Failover Cluster should have only DR servers and Cluster Name & File Share Witness resource should be online
Primary Active Manager should be showing in the DR site.
-
Move OAB to the DR site: Move OAB generation server from Production to the DR.
- Login to DR server
- Open Exchange management Console and go to Organization Configuration à Mailbox à Offline address book tab.
-
Right click on Default Offline Address Book then select move, then select the DR server and click on move.
- Login to DR server
-
Change internal DNS host record for CAS to the DR site
-
Change the send connector source servers to DR server if you have just one send connector. Normally we can configure 2 send connectors one for Production source servers and other for DR source servers.
-
Change the CAS Array site:
- Login to DR server
- Open Exchange management shell
- Run the cmdlet to get current site
Get-ClientAccessArray -Identity CASArrayname | fl site
Run the cmdlet to change the CAS array to DR site
Set-ClientAccessArray -Identity CasArrayName -Site DR site
Run the cmdlet to verify the change.
“Get-ClientAccessArray -Identity CasArrayName | fl site”
- Login to DR server
-
Change the Public Folder Server: Change the Public folder server to the DR public folder server.
- Log in to the DR Server
- Open Exchange management shell.
-
Run the below cmdlet
Set-MailboxDatabase -PublicFolderDatabase “Name of the DR PF DB”
- Log in to the DR Server
-
Perform forest wide Active Directory Replication: Perform forest wide AD replication so that all DNS and AD server gets replicated with the updated information and all clients connect to the correct mailbox servers.
-
Backup the following using DPM:
- System State backup.
- Exchange backup using DPM.
- System State backup.
Your DR plan implementation should be complete now.
In the next part of the article, we will take a look at Part 2 – Switchback to the Production Site – https://msexchangeguru.com/2012/10/30/exchange-2010-dag-dr2
Prabhat Nigam (Wizkid)
Team@MSExchangeGuru
Please note that if you need assistance in performing disaster recovery, we can help you with the same. Send an email to prabhat@msexchangeguru.com and mark ratish@msexchangeguru.com and one of us will get back to you.
")


October 30th, 2012 at 1:16 pm
[…] Exchange 2010 Cross Site DAG Disaster Recovery: Data Center/AD Site failure Part 1: https://msexchangeguru.com/2012/10/25/exchange-2010-dag-dr/ […]
March 16th, 2013 at 12:56 am
Great post. Thank you Team
March 23rd, 2013 at 2:02 pm
Sir,I have a Doubt about a domain controller that seized can’t get back online in primary Site. If there is already existing a additional DC in Primary Site and seized DC that we can’t get back online then can I replace it with clean installing by Same name or have to assign different name to that DC and clean Metadata of seized DC. which will work better in DAG Failback Situation?
Please guide me for the same scenario.
March 23rd, 2013 at 3:31 pm
Hi Krishna,
Yes, we should not bring the seized DC in the environment.
You can segregate seized DC from network then turn it on, do the dcpromo /forceremoval, clean the metadata, delete AD object from AD and rejoin this DC to the domain and install AD again on this DC. This can be done within 1 hr. If you can afford more time can then you can format this server as well.
Yes you can use same name if you have cleaned metadata.
Prabhat
May 2nd, 2013 at 8:49 am
Thanks.
October 23rd, 2013 at 12:10 pm
Hi Folks,
Can anybody let us know what settings should be identicle between production & DR site for Exchange 2010?
Regards,
Prashant Sahane
October 23rd, 2013 at 2:52 pm
All exchange configuration should be identical except PF database. In DAG you would need to add DR Sites Cluster IP as well.
And IPs will be different by default for servers, load balancer and Public IP.
January 7th, 2014 at 3:20 am
Excellent post. I used to be checking constantly this blog and
I’m impressed! Very helpful info specifically the final phase
🙂 I care for such info a lot. I used to be looking for this certain information for a very long time.
Thank you and best of luck.
April 23rd, 2014 at 9:54 am
Great Post !
What if we have all servers on both Pirmary (4 nodes ) and DR (3 nodes) sites up and running and we want to shut down for maintenance all servers on the primary site without having the DAG going down ?
Stop-DatabaseAvailabilityGroup -Identity DAGname -mailboxserver ProdDAGservername1 –ConfigurationOnly ,
does not seem to remove the server in the count of the node majority ?
and if I stop all the servers (4 nodes)on the primary sites , the DAG will go down as not enough members will remain online …
Thanks !
April 23rd, 2014 at 10:47 am
@Kevin,
This command will remove your server from the cluster so be careful with this command.
Stop-DatabaseAvailabilityGroup -Identity DAGname -mailboxserver ProdDAGservername1 –ConfigurationOnly
Normally we don’t remove a server from cluster when we shutdown the server for maintenance. In your case you have seven node dag, when you plan to shuddown all 4 means all VMs are in one virtualized host which is going down for maintenance. I would recommend 2 Virtualization host to avoid this situation. I would say use this command for one server.
You might need to restart the cluster service on all servers to reflect it.
Now you have 6 nodes so make sure FSW is up.
Move the cluster using the command- Cluster.exe dagfqdn group “cluster group” /Moveto:nameoftheDRSiteServer
Move active database to the DR site.
You should be good to shutdown the servers.
April 23rd, 2014 at 10:56 am
Thanks a lot for you quick answer
Yes , I wish I could have them on 2 Virtualization Host … but unfortunately … I have not the choice 🙂
My understanding is that if I want to shutdown the 4 nodes on the primary site , I have to remove 3 servers from the DAG ? 4/2 + 1 = 3 , so the 3 active nodes on the DR site will be enough to keep the DAG alive ?
When I want to readd the server to the DAG , can you tell me if I will have to reseed the whole database ? or just restart copy might be enough ?
April 23rd, 2014 at 6:08 pm
@Kevin
You should be good by removing just 1. 6/2+1=4
Review the Part 2 to readd– Switchback to the Production Site – https://msexchangeguru.com/2012/10/30/exchange-2010-dag-dr2
I am sure you can find the steps from there. No need to reseed.
May 29th, 2014 at 9:43 pm
Hey Guys
I am reviewing some documentation for a partially failed data center and don’t understand this part here :
Failure to either turn off the Mailbox servers in the failed datacenter or to successfully perform the Stop-DatabaseAvailabilityGroup command against the servers will create the potential for split-brain syndrome to occur across the two datacenters. You may need to individually turn off computers through power management devices to satisfy this requirement.
I thought DAC mode prevented Split-Brain, that’s what i was always taught. Here is the link:
http://technet.microsoft.com/en-us/library/dd351049%28v=exchg.141%29.aspx
Thanks
May 30th, 2014 at 12:48 am
@Rob
Very nice question
DAC mode prevents Split brain for sure but this document is talking about activating DR site understanding it is a complete outage in primary site so if you are doing a DR test then you might like to shutdown all production servers else it is going to cause big issue. The reason is different information in AD and 2 DCs claiming master roles. Again you would like to be on safer said rather than messing up the environment.
I hope this clear your doubt. You are most welcome to raise your concerns.
September 21st, 2014 at 6:30 am
Just to add to above.
Restore-DatabaseAvailabilityGroup -Identity DAGname
actually evicts the node from the primary Site .(note: it just removes the cluster nodes from the failover cluster manager. It doesn’t remove the node entries from AD)
So when you run the command Start-DatabaseAvailabilityGroup -Identity DAGname it pulls the information from the AD.
Understanding of DAC Mode:
All the nodes in the DAG have a DACP set in the memory.
This is actually to prevent split brain syndrome.
When it is DAC mode enabled . it checks for 2 options:
The node is able to communicate with another server which has DACP bit enabled.
If it is able to communicate with all the other servers in the cluster .it will set its DACP bit to true.
September 24th, 2014 at 9:16 am
Thank you for adding the description. The purpose of the blog is to do the DR so description of the steps was not required.
October 1st, 2014 at 3:49 pm
Excellent post. Always big help. It’s always good to know and keep it handy because one day. Thank you Team.
October 9th, 2014 at 4:30 pm
Excellent article. Thanks for writing it, it clarified many doubts I had about the process while raising a single, important question:
This being for a DR test… what would happen in the event of a REAL disaster? Say our data center in Los Angeles disappears during an earthquake. There will be no time and no means of doing any of these steps for quite some time. We’ve been under the impression the DAG would failover automatically to the DR data center but that appears not to be the case. Can you share your thoughts on the matter?
Thanks.
October 9th, 2014 at 6:51 pm
In 2010 DR will be manual.
In 2013 DR will be automatic.
July 2nd, 2015 at 7:52 am
Hi ,
i have read your post it was really interesting but i have one doubt on that there is one point,
Change internal DNS host record for CAS to the DR site
what do you mean by,
means i have 4 CAS server in cas array, do we need to change all 4 server to DR AD site,
i am confuse on this point,
and why not we change just cas array ip to working CAS array in DR site,
waiting for your response ,
Thanks & Regards
Bharat Kumar
July 2nd, 2015 at 12:33 pm
It is for the cas url in you DNS